Story points are a pretty ubiquitous part of Agile by now. In Agile, we use the idea of story points to add a layer of abstraction to estimation, to allow us to estimate based on relative size, and to stop ourselves from ascribing a false level of precision to our estimates. One thing that is always described as an Agile Anti-Pattern is basing your estimates or story points on how long one believes something will take to complete. Let’s take a bit more of an in depth look at why that is.
The premise
Throughout this example, I’ll be representing work being done in the form of eating apples, and other foods may make a guest appearance. Apples are generally of a similar size and makeup to one another, and assuming there are no worms, they are also of similar complexity and risk, so we’ll use those to represent items of work that are also of similar sizes and makeups.
Everyone doesn’t work at the same rate
Let’s start with two apples. We’ll give two different people one each of those apples. Without any other context, you may believe that these two people will take about the same amount of time to finish eating those apples, and that may, in fact, be true. But what if one of those folks is a child? Or a world class speed-eating champion? The time they will be working on eating the apple may vary, but the outcome is the same: one eaten apple.
It’s the same when looking at work. Two people may take a different amount of time, even working on the same item, due to a number of different factors. That doesn’t change the size of the item being worked on, or the value you’ll derive from it’s completion.
Outside factors can change the time to complete
Other factors can also effect how long it takes to do something, without changing the size of what you’re doing. Let’s take one person eating one apple. Did said person just eat a huge lunch? Maybe they’re having dental issues? Any number of factors can change how long it will take to eat the apple, without changing the size of the apple.
The same can be said about a story. There may be outside dependencies or blockers slowing down progress on an item, but that doesn’t change the size of the story itself, just the speed at which it can be done. Padding estimates due to known external factors comes with it’s own set of concerns, but suffice it to say that it doesn’t do any one any favors. (Note: This is assuming similar levels of uncertainly and complexity. Stories lacking clarity or those which are highly complex should be estimated higher… it’s a good lead in to another post for another time)
Improvements are not properly reflected, or hard to see
This time, lets take one apple, to be shared by a family. This family can take bites of the apple, and pass it around until it’s finished. By doing this, the family can eat one apple in 20 minutes, so lets say it earns them one “food point” in 20 minutes. The family talks about it, and they determine they can share the apple better by slicing it, and eating pieces at the same time. This lets the family eat two apples in the same 20 minute time period. Now, if they base the “food point” on the time it takes to eat the apple, and they said 20 minutes is the basis for a food point:
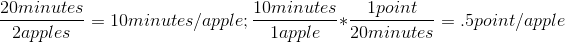
This means by improving their apple-eating methods, they actually decreased how many points an apple is “worth” in their scale. Note the apples haven’t changed in size, complexity or value.By doing this, the family’s velocity is 1 point, as they are still doing 20 minutes of work, however they completed twice as much.
Now, let’s base the points on the work item itself, by saying 1 apple = 1 point. Originally, they had completed 1 point per 20 minutes, and now they can complete 2 in the same time frame. Therefore, their velocity increased from 1 to 2. (Also, look how much more simple that math was! Work smarter not harder…)
At the end of the day, both of these mean the same thing: twice as much work is being done in the same time period. However, by basing our abstraction on the work as opposed to the time the work “should” take, it is far easier to track how much our actions effect our output.
In conclusion
With estimation, we take a guess as to how big things are, to help us plan and scope. We understand it is a guess, so we abstract this guess, so that we focus more on being roughly right as opposed to precisely wrong. When we abstract, it’s important to base our abstractions on values that can the most consistent and easiest to compare to a baseline, and in most cases, its generally work being done.
Questions about this, or comments? I’m always up for a good discussion. Please drop me a line in the comments below!
